Learning Apache Spark with a quick learning curve is challenging. Discover distributed computation and machine learning with PySpark, with several tutorials until building your movie recommendation engine.
Links: GitHub | Tutorials quick start | Dataset
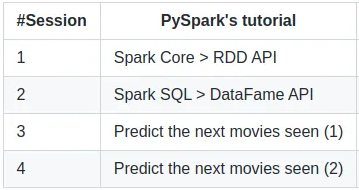
Let’s discover how to use PySpark on Google Colab with accessible tutorials.
As a teaching fellow with David Diebold about Systems, paradigms, and algorithms for Big Data for the international Master IASD (graduate degree M2) for the French Dauphine Paris University member of the PSL University, I needed to organize sessions of tutorials for the students on the distributed computation with Apache Spark.
Fast, flexible, and developer-friendly, this data-distributed processing framework has become one of the world’s most significant. Before teaching the features provided by Spark, we had to choose which language and platform our learners could run the tutorials we prepared. We chose the tech stack: PySpark with Google Colab.
PySpark vs. Spark
PySpark allows interaction with Spark in Python. It gives a better learning curve than Spark (written originally in Scala). Even though it is less performant for a production world using Py4J to interact with the JVM of Spark, it gives sufficient performance (sometimes close to Spark with Java/Scala) to experiment with distributed data science and machine learning.

PySpark with Python remains largely the preferred language for Notebooks.

The support of PySpark is already excellent and continues to be improved with the future version of Spark 3+.
Python is easier to learn than Scala and has a mature ecosystem for applied mathematics.
For these reasons, we preferred teaching PySpark over Spark. Moving from one to another is easy, only the cost for the learners to become familiar with the Scala/Java ecosystem for advanced use.
👀 Read more
Read the rest of the article …




Comments